Vision Transformer finetuned without augmentation
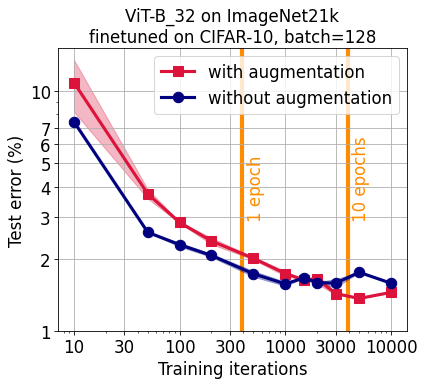
A Vision Transformer (ViT) pretrained on ImageNet21k finetunes significantly faster without training set augmentation for short optimization schedules on CIFAR-10 (<3 epochs) and CIFAR-100 (<7 epochs). Despite this, the official GitHub repository ViT finetuning Colab uses augmentation by default. It might be worth turning it off for your experiments to speed things up and save compute. If you are willing to run longer finetuning, augmentation gives a slight accuracy boost.
Stanislav Fort (Twitter, Scholar and GitHub)
| Finetuning on CIFAR-10 | Finetuning on CIFAR-100 |
|---|---|
 |
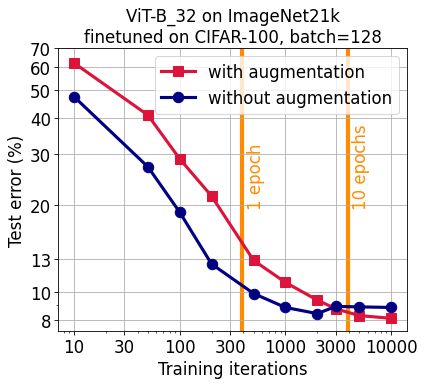 |
Quick summary: The original Google Research GitHub repository has as ViT finetuning Colab which uses training set augmentation by default. However, given a fixed compute budget, not using augmentation seem to lead to a higher test accuracy for shorter finetuning schedules (<3 epochs for CIFAR-10 and <7 epochs for CIFAR-100). Speculatively, this could be due to the sufficiently strong prior the pretraining imparts on the network that doesn’t have to learned from the finetuning dataset directly. The benefit of augmentation for such prior development in a weaker network might here be overshadowed by the downside of potentially unnaturally broadening the class definitions. For longer finetuning, training without augmentation leads to slightly worse test accuracy.
Motivation: I have randomly noticed that the Vision Transformer pretrained on ImageNet21k, as shown in the Google Research GitHub repository and in their Colab, finetunes on CIFAR-10 and CIFAR-100 faster when I turn off the training set augmentation that is on by default. This is true for short finetuning schedules. I have been telling people on a one-by-one basis when a conversation got there, but thought writing it up might be useful for others. We have noticed this effect in our recent paper Exploring the Limits of Out-of-Distribution Detection where test accuracy corresponds well to models’ out-of-distribution capabilities.
Experiment: I am using a single Vision Transformer, ViT-B_32, pretrained on ImageNet21k. I am then finetuning on CIFAR-10 and CIFAR-100 with a new head of the appropriate number of classes. The finetuning is applied to the full model including head, rather than the head alone. The default data preprocessing in the Colab involves a simple set of augmentations. For finetuning, I am using the default learning rate schedule: 5 iterations of a linear learning rate growth for as a warm up, followed by a (total steps - 5) steps of a cosine schedule. I varied the total number of steps in the schedule, keeping the 5 initial warm up steps constant. The batch size I used was 128. The Colab finetuning settings were:
warmup_steps = 5
decay_type = 'cosine'
grad_norm_clip = 1
accum_steps = 8
base_lr = 0.03
Results: Broadly, the longer the schedule, the better the final test accuracy. This stops being true for training without augmentation for >3 epochs for CIFAR-10 and >7 epochs for CIFAR-100. For short schedules (<3 epochs for CIFAR-10 and <7 epochs for CIFAR-100), finetuning without augmentation has a large advantage over training with augmentation. For longer schedules, the gap narrows and augmentation eventually leads to slightly higher test accuracies. See the plots at the top of this post for details.
After talking to Ekin Dogus Cubuk on Twitter, I looked at longer finetuning schedules and noticed that fore those augmentation has a slight benefit for test accuracy.
Conclusion: For quick finetuning of the Vision Transformer on CIFAR-10 and CIFAR-100, not using training set augmentations will likely save you training time and compute. This is speculatively due to the strong prior imparted by the massive pretraining and rapid few-shot generalization of the Vision Transformer. For longer finetuning (>3 epochs for CIFAR-10 and >7 epochs for CIFAR-100), augmentation has a small test accuracy benefit. The specific numbers likely depend on my choice of learning rate, learning rate schedule, and batch size.